
How Prefect (and a Beefy Hetzner Auction Box) Rules Our Price-Tracking Empire

I've talked multiple times about my goal to build a price-tracking empire. What started as a single, fragile app back in 2016 has evolved into a multi-region, multi-store data operation.
But when you're dealing with millions of products across Bol.com, Walmart, and beyond, your code can quickly turn into a chaotic spaghetti monster of broken scripts. As we started scaling up, I brought in some talented freelancers to help speed up development. Best decision ever. One of them introduced Prefect to our stack, and it completely changed the game for our orchestration.
Here is exactly how we use Prefect to run our data pipeline, and the exact infrastructure making it happen for cheap.
The Infra: DigitalOcean Apps Meets a Hetzner Auction Beast
I used to worry about creeping infrastructure costs, but I've finally found the sweet spot between cloud flexibility and raw hardware power:
- The Frontends: The actual customer-facing price tracking websites (like Prijzenvolger and Walltrack) are hosted on DigitalOcean Apps. It's clean, isolated, and handles web traffic beautifully.
- The Heavy Lifting: Everything else lives on a absolute beast of a server I scored in the Hetzner server auction. It came with a massively beefy memory setup and nvme setup, perfect for data crunching. And because it can handle all our memory intensive data flows and has enough storage to last us a 8 years, we're set for a while
- The Deployment: We use Ansible to manage the server configuration. Everything on this Hetzner machine; our databases, our queues, and our Prefect flows, is completely dockerized.
The Data Layer: Polyglot Persistence Done Right
Running dockerized on our Hetzner box is a polyglot data stack where every tool does what it's best at:
- PostgreSQL: Handles our relational data (product catalogs, user accounts, price watches).
- ClickHouse: The ultimate OLAP machine. It handles our massive, high-volume time-series price history. Every single price tick goes here.
- Vespa & Redis: Vespa handles semantic search, while Redis keeps track of runtime configs and rate limits.
Our codebase follows a strict rule: flows.py only contains high-level Prefect flow definitions. All actual business logic lives inside a tasks/ directory and is imported lazily inside each flow.
Let's see how that looks like for Prijzenvogler:
1. The Core Pipeline: Fan-Out Data Ingestion
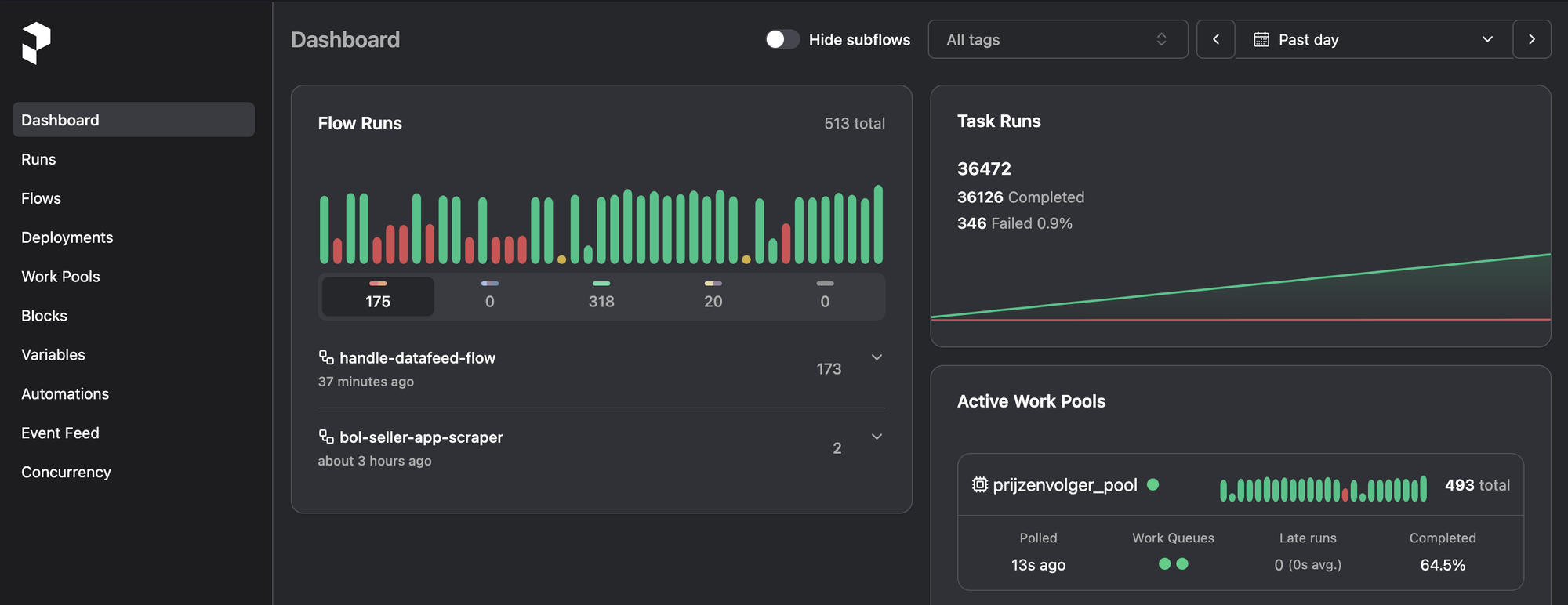
The heart of Prijzenvolger (our Bol.com tracker) is the handle_datafeed_flow. It runs a strict Fetch → Process → Store pipeline inside its Docker container.
- Fetch: Connects to Bol’s FTP server via FTPS, checks for duplicates, and downloads the gzipped data.
- Process: We use Pandas to crunch the pipe-delimited CSV. Because Bol handles both the Netherlands (NL) and Belgium (BE), we split the data into parallel tracks and convert prices to clean integer cents.
- Store: Prices get dumped into ClickHouse. Products get an
UPSERTinto Postgres.
The Postgres Partitioning Gotcha ⚠️
Because our Postgres product_product table is heavily partitioned for speed, it won't expose xmax. That means the classic RETURNING (xmax = 0) trick to see what rows are genuinely new doesn't work. Instead, we pre-query existing IDs per chunk to figure out what's new. Only those brand-new products are then pushed to Vespa for search indexing.
The 25x Fan-Out
Instead of writing a massive, slow flow, we wrote one generic flow and fanned it out 25 times using flows.yaml. Each deployment targets a specific category (e.g., electronics, books) with staggered cron schedules every 2 to 6 hours. This spreads the database and FTP load perfectly across our Hetzner RAM.
2. Deal Finder & User Alerts
- User Alerts (
check_price_watches): Runs every 5 minutes. It grabs unfulfilled alerts, groups them by product so we only hit the live Bol API once per product, and fires off an email if the price drops. - "Speurder Prikkie" Deal Finder (
update_hot_products): An hourly ClickHouse query compares today’s latest price against yesterday’s max. We only keep drops between 20% and 70% (under 20% is boring; over 70% is usually bad store data). It uses a unique index in Postgres to remain completely idempotent.
Bonus: My Personal "Agentic" Prefect Stack
I fell so hard for Prefect while building this empire that I didn't stop there. Aside from the price tracking workflows, I have set up a completely separate, private Prefect stack on my infrastructure.
I use this secondary stack exclusively to run my own agentic flows—orchestrating AI agents, automated workflows, and LLM experiments. Having a reliable, UI-driven playground to monitor complex, multi-step AI tasks has been an absolute game changer.
Why This Setup Wins
By combining Prefect's orchestration with a split Postgres/ClickHouse architecture running on an auctioned Hetzner box, we get zero data corruption, real-time price accuracy, and incredibly low overhead.
For anyone exploring a character design, it is worth considering how details related to women's cosplay costumes will affect the complete look. When comparing costume options, a comparison of details related to convention planning can clarify differences in colour and construction. To shape a complete look around details related to beginner costume choices, game cosplay costumes with fabric details offers a useful starting point for practical preparation. To stay comfortable throughout the event, a balanced view of details related to long cosplay wigs can support both detail and comfort.
The empire is growing, the workflows are automated, and the data is clean. As someone who always wanted to be a solopreneur, it's actually refreshing to work together with people on a project, and have them recommend tools that end up changing the business in a very positive way
Stay tuned for the next update!